Data Gathering Case Studies
Research infrastructure, pipelines, and monitoring that make downstream analysis trustworthy.
These projects focus on the ingestion patterns, alerting layers, documentation systems, and streaming pipelines that let quant, analytics, and product teams operate without guessing what the data means.
Quant Data Platform Roadmap - V0 to V3
A capability-first roadmap for sequencing reproducibility, governance, and optional low-latency without turning platform work into theatre.
Read full case study
Alerting the Chain - Rate-limits to PagerDuty
How we turned fragile reserve checks into a severity-based alerting path with Slack for triage and PagerDuty for real incidents.
Read full case study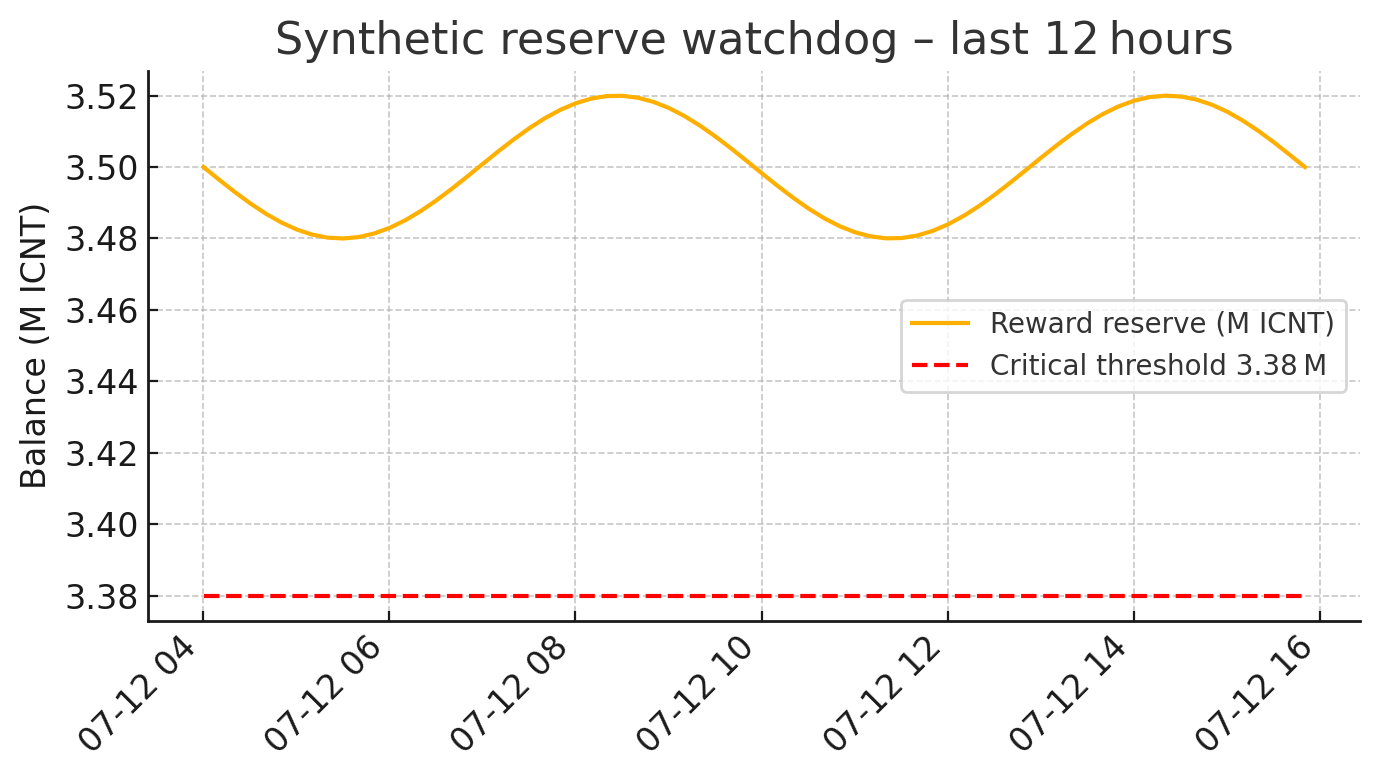
Real-time Market Feeds - Streaming Delta to Tableau
A practical streaming pipeline for market data, spread snapshots, and presentation-layer tables that analysts could trust.
Read full case study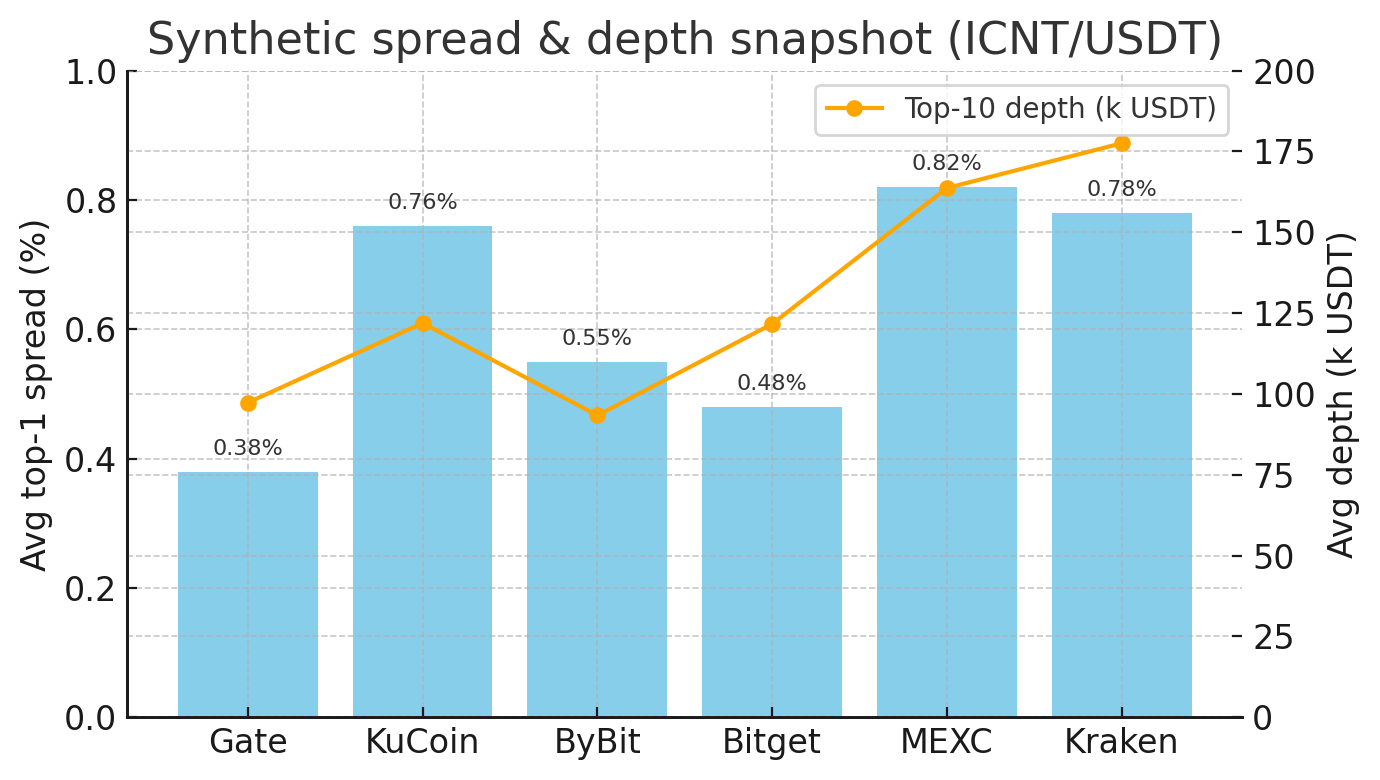
Documentation Sprints at Warp Speed - Shipping the Node Sale GitBook
A two-week push that turned scattered notes, diagrams, and economics content into a public docs system the commercial team could actually use.
Read full case study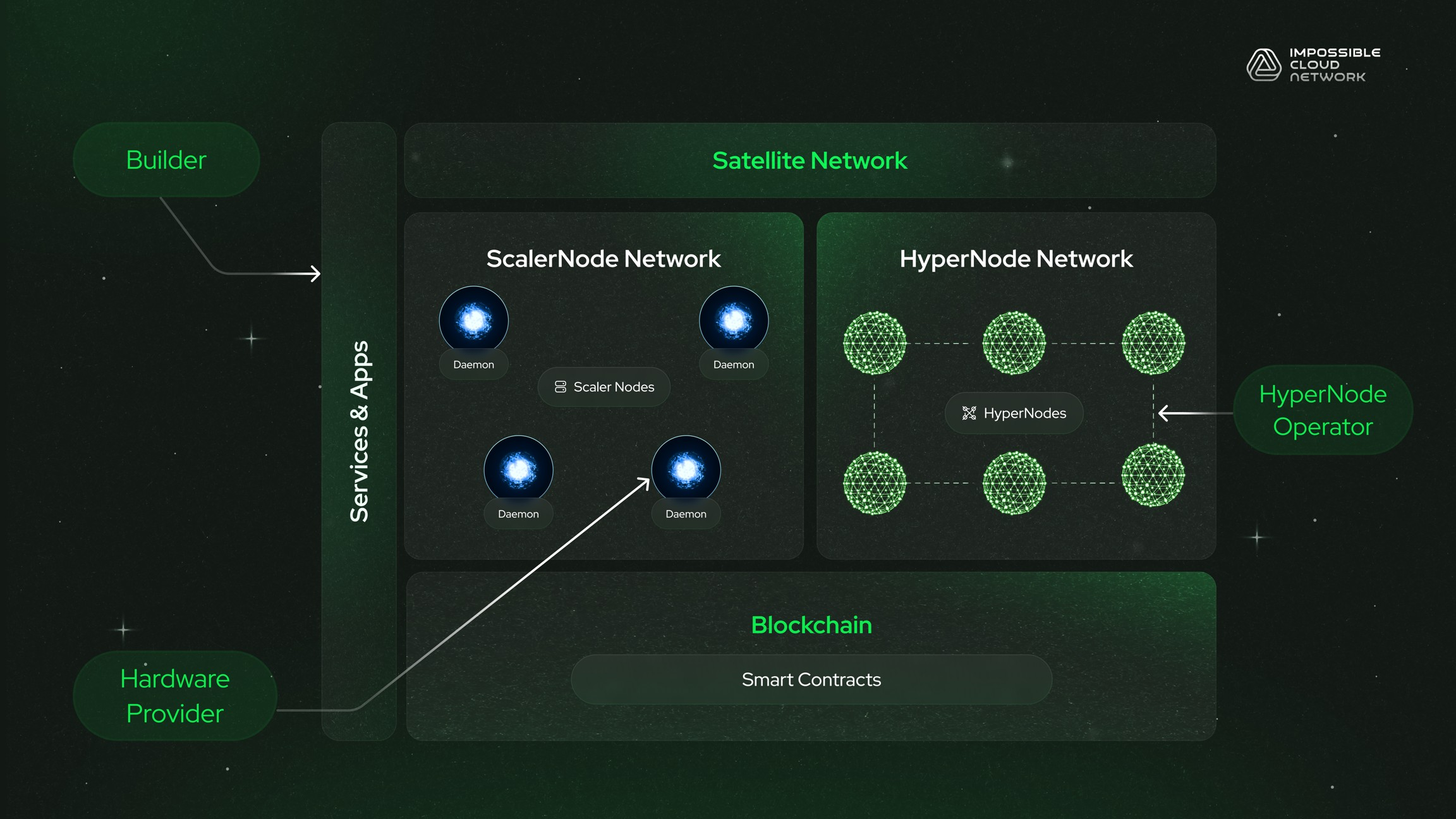
Scraping the Android Paid Rank Charts
Building a lightweight mobile-intelligence feed for ranking, pricing, and install signals while keeping the data collection process explainable.
Read full case studyAutomating Documentation with DBT and Jenkins
Using CI to keep analytics documentation live, versioned, and easy for non-engineers to find without manual rebuilds.
Read full case study
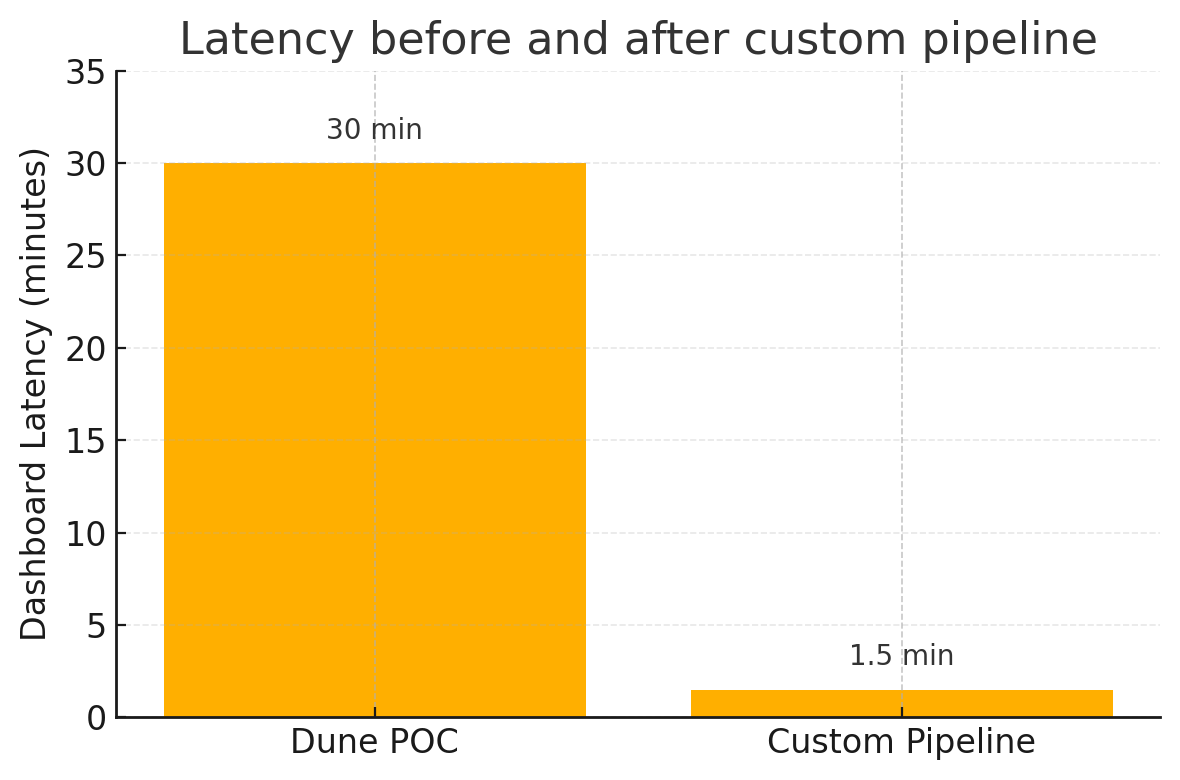
Beyond Dashboards - Mining Dune, Then Building Our Own
Dune was the fastest proof of concept for on-chain visibility, but the production answer needed our own mixed on-chain and off-chain pipeline.
Read full case study